This video and post are part of a One Dev Question series on MLOps - DevOps for Machine Learning. See the full video playlist here, and the rest of the blog posts here.
As a software developer, it can be tempting to use or recommend the tools you're used to when implementing MLOps. In some cases, the tools you already use are great, but in other cases they're really not fit for purpose.
There are countless tools people use for managing their software delivery lifecycle. We all have our favourites (VS Code, GitHub, Azure DevOps, and Azure Monitor are mine), but they (and the majority) are focused around traditional software development.
That's not to say that these tools can't be used for machine learning projects, but many aren't designed for those workflows.
Source Control
In the last post, we talked about source control, so let's use that as a simple example.
Keeping all your python or R code in a git repository makes sense, along with your training and inferencing environment specifications and any other infrastructure-as-code. But as we saw, data is a different story.
If you're using Azure Machine Learning, tools like the built-in versioning capabilities of datasets can be exceedingly useful. If used properly, this can enable you to effectively version your training data each time it changes or as needed.

Continuous Integration / Training
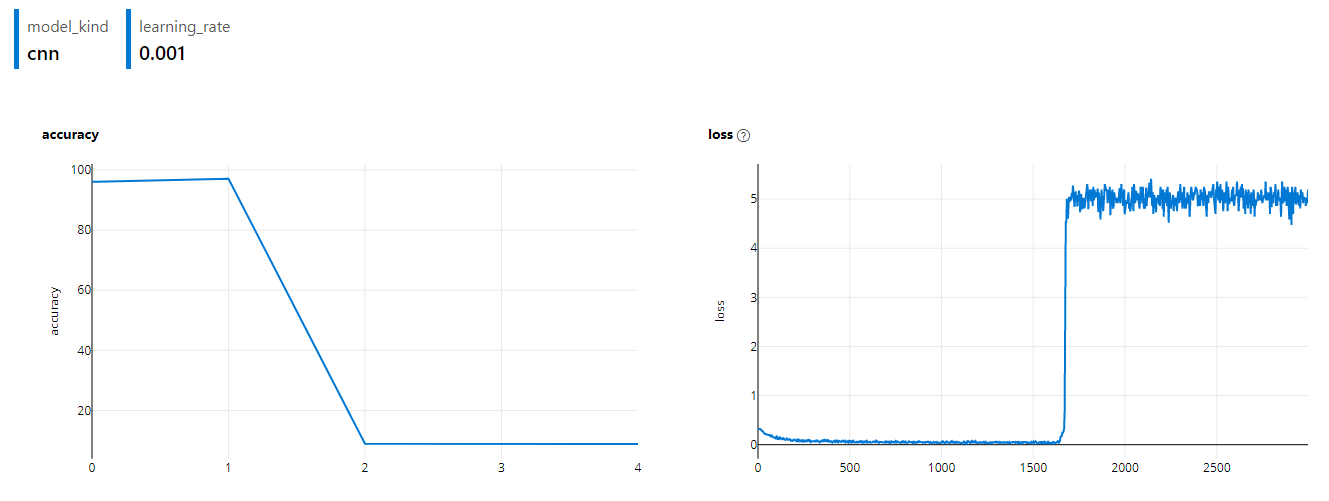
Similarly, in part 6 of this series, we noted that traditional "continuous integration" strategies were unlikely to work due to the data- and computationally-intensive training process. If every change leads to a full training run, you better have extremely deep pockets.
Even if money is no object, the fact that these training runs usually take much longer than traditional software projects means the CI/CD tooling is unlikely to handle it well.
For example, GitHub Actions has a limit of 72 hours for a workflow run. This sounds like a lot (and it is considering so much is free), but if you're using GitHub-hosted runners, each job in that workflow can only run for 6 hours. That's plenty of time for all but the most extreme software builds, but it's unlikely to be enough for serious machine learning training runs. Of course, if you can get your training done in under 24 hours, you might be able to get away with self-hosted runners - but then you're managing the infrastructure yourself.
But let's assume you can effectively run your training in that time. Because these systems aren't built for working with large amounts of data, you'll have to consider how you get access to and use that data efficiently. You'll also probably want to monitor the progress of your experiment visually rather than trying to parse through logs.
Tools like Azure Machine Learning are built around these specific requirements, so they're better suited to the task.
But even if it's not advisable to do the actual training there, GitHub Actions is a great place to trigger a workflow when something changes - especially code.
For example, you might modify your code to try a different activation function. You run a few tests locally with a subset of data and are confident it's worth a try. So you commit and push the change.
GitHub Actions can react to that commit by kicking off a workflow - passing control to . That workflow might use the actions for Azure Machine Learning to update and run a new training pipeline (learn how here), and send a message to a Teams channel to let the team know there's a new training run, complete with links to the experiment itself.
Deployment and Monitoring
Controlling the actual deployment of a predictive model - ideally in an isolated, portable format - is a task that can absolutely be done with traditional DevOps tools. In terms of portability, one common delivery technique is wrapping the predictive model in a docker container, so it can be deployed anywhere and scaled as required.
In fact, most of the behaviours you'd want to emulate when going to production are the bread and butter of standard deployment automation tools. Gradual rollout techniques like canary deployments, rolling deployments, using deployment rings, and even A/B testing of models or shadow deployments can be handled beautifully by tools like Azure Pipelines. After all, at this point, you have a piece of software that needs to be deployed. Where it came from is not relevant if the deployment method is the same.
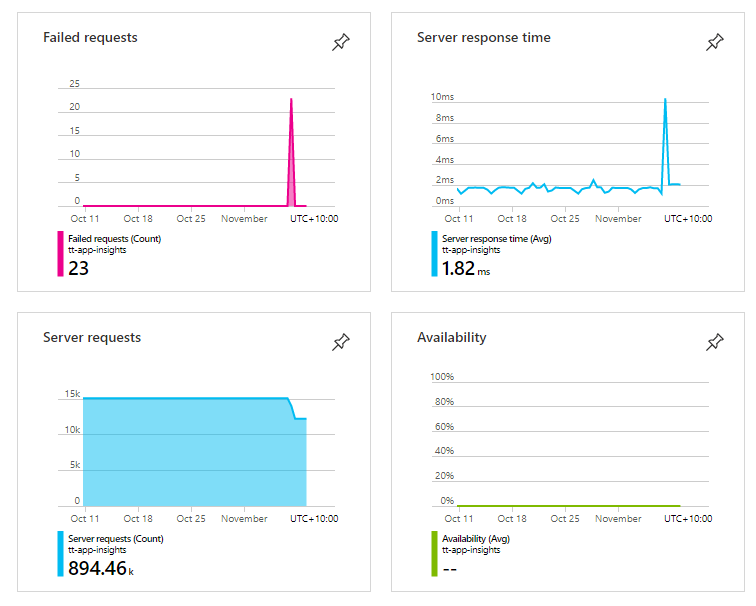
Similarly, monitoring how your model is being used in production can be handled effectively by existing DevOps tooling. Provided the right logs and events are being produced by your model (or any software), Azure Monitor can give you all the insights you need.
In summary, you can use many of the tools you're used to for traditional software development:
- Git is great for any text-based file versioning and collaboration.
- GitHub Actions and Azure Pipelines are great at kicking off pipelines
- Azure Pipelines is fantastic at carefully controlling rollout of your model
- Azure Monitor can be used to observe what your model is actually doing in production
BUT the actual training should be done using specialist tools, and you'll need to consider how you're going to version and access data both day-to-day and during training.